ARC-AGI-3: What Interactive Reasoning Benchmarks Change for Agent Design
ARC-AGI-3 is the first ARC release where the implementation details matter as much as the reasoning story you tell about them.
In ARC-AGI-2, a strong solver could still look like a clever function from input grid to output grid. In ARC-AGI-3, that abstraction breaks down. The benchmark asks an agent to act inside an environment, update its beliefs after each step, and avoid wasting moves on blind exploration.
That shift is why the benchmark is useful. It forces you to inspect the full control loop:
- what state the agent keeps
- how it converts observations into hypotheses
- how it decides whether to explore or exploit
- how much extra compute it burns while doing all of that
The practical question is no longer, "Can the model guess the right answer?" It is, "Can the system learn the environment fast enough to solve the task without wandering?"
1. What Actually Changed in ARC-AGI-3?
Previous ARC tasks were static visual puzzles. The hard part was inferring the latent rule from a few examples. ARC-AGI-3 keeps the latent-rule idea, but moves it into Interactive Reasoning Benchmarks (IRBs) where the agent must act, observe the result, and adapt.
That sounds like a small change. It is not.
Once the benchmark becomes interactive, the solver can no longer treat the problem as a single forward pass. It needs a loop. It also needs a representation of uncertainty: not just "this is the rule," but "this might be the rule, and here is the cheapest action that would confirm it."
Two public tasks make that difference obvious:
- LS20 (Latent State Navigation): the agent is in a maze with a locked door and has to discover that its own shape can be rotated to match the lock condition. This is not just pathfinding. It is pathfinding plus hidden-state discovery.
- FT09 (Discovery via Click): the agent acts in a $64 \times 64$ click space and has to discover which parts of the scene are actionable. This turns action selection into an information-gathering problem.
The key change is that wrong actions are no longer just wrong outputs. They consume budget, alter state, and sometimes make later reasoning harder.
2. Why Action Efficiency Changes the Engineering Problem
ARC-AGI-3 does not only care whether your agent eventually solves the puzzle. It cares how many actions it used relative to a human baseline.
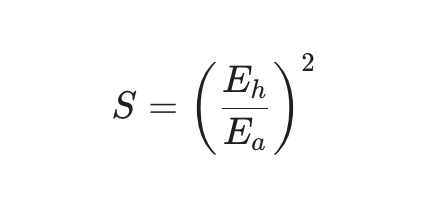
If a human needs 10 actions and your agent needs 100, you did not build a slightly worse human. You built a solver that probably does too much search, stores the wrong abstractions, or cannot tell the difference between useful exploration and noise.
This matters because action efficiency exposes a class of systems that look impressive in demos but collapse under measurement:
- agents that repeatedly restate the same plan in different words
- agents that use environment steps to discover things they should have tracked in memory
- agents that recover from every small mistake with a full replanning cycle
- agents that hide weak policies behind large amounts of inference-time compute
In practice, ARC-AGI-3 is not just a reasoning benchmark. It is also a tax on sloppy control flow.
That makes it a useful proxy for workflow automation too, but only if you keep the analogy honest. A legal triage system, for example, is not a maze. Still, the same failure mode appears: too many unnecessary actions usually means too many unnecessary tool calls, state transitions, or review loops.
3. A Minimal ARC-AGI-3 Agent Loop
In my own experiments, the most useful starting point is not a giant multi-agent graph. It is a small control loop with explicit state.
state = init_episode()
while not state.done and state.steps < max_steps:
observation = observe_environment(state)
belief_state = update_beliefs(state.memory, observation)
candidate_actions = propose_actions(belief_state)
action = select_action(candidate_actions, belief_state)
next_observation = env.step(action)
state = commit_transition(state, action, next_observation)
That looks almost trivial, but each line hides a real design choice:
update_beliefsdecides what gets remembered versus recomputed.propose_actionsdetermines whether the system explores broadly or narrows quickly.select_actionencodes your bias toward information gain, shortest path, or risk reduction.commit_transitiondetermines whether the agent accumulates a compact world model or an unreadable transcript.
If I were turning this section into a diagram, I would draw it as:
Environment -> Observation Parser -> Belief State -> Action Proposal -> Policy Selector -> Environment
Then I would add two side channels:
- a persistent memory store that feeds Belief State
- a rollback or replan branch that triggers when the last action falsifies the current hypothesis
That diagram is often more useful than a screenshot of a benchmark leaderboard, because it forces you to ask where the errors are actually coming from.
4. Where LangGraph Helps, and Where It Adds Cost
It is easy to see why teams reach for LangGraph-style architectures here. Interactive tasks naturally decompose into roles such as perception, planning, and execution, and a graph runtime gives you checkpoints, state passing, and explicit transitions.
The pattern is reasonable. A three-node loop like this is easy to justify:
- Perceiver: turn raw observations into structured state.
- Strategist: generate or revise the current hypothesis.
- Executor: choose and issue the next environment action.
That said, the graph is not free.
In the messy middle, I kept running into trade-offs that are easy to ignore in architecture diagrams:
- Serialization overhead: rich graph state is useful until every node starts passing bloated transcripts instead of compact facts.
- Latency stacking: multiple nodes can improve traceability while making each environment step much slower.
- Debugging ambiguity: when the agent fails, it is not always obvious whether the bug was in perception, strategy, routing, or memory.
- Checkpoint temptation: persistent checkpoints are helpful, but they can also encourage over-engineering when a simple finite-state loop would be easier to reason about.
My current view is pragmatic: start with a plain loop, add graph structure only when you can point to a concrete failure that the graph solves.
If the task mostly needs deterministic state updates plus occasional hypothesis revision, a hand-rolled controller is often enough. If the task genuinely benefits from branching subplans, human interrupts, or resumable long-horizon execution, a graph runtime earns its keep.
5. Translating the Benchmark Into Real Workflow Design
The most productive way to use ARC-AGI-3 is not to say, "This proves the benchmark matches my business." That is usually too loose.
The better move is to borrow the benchmark's structure.
For example, I have been using Australian Consumer Law (ACL) triage as a thought experiment because it has exactly the kind of stateful branching logic that static benchmarks miss. A return or refund dispute is not one question with one answer. It is an evolving environment with observations, legal constraints, missing information, and points where the system should stop and ask for a human decision.
The useful mapping looks like this:
- Observation: customer complaint, product type, timeline, evidence provided
- Latent state: whether the issue is likely a major failure, minor failure, service issue, or insufficiently specified case
- Valid actions: request more information, present remedy options, escalate, pause, or finalize
- Penalty for bad policy: wrong legal path, extra handling time, and unnecessary back-and-forth
That framing is much more actionable than generic claims about "AI for compliance." It gives you a state space, a decision policy, and a way to score the system.
If you want to evaluate an agent in a workflow like this, do not just check final accuracy. Track:
- steps to resolution
- unnecessary tool invocations
- number of state reversals
- escalation rate
- cost per successful episode
That is the real lesson from ARC-AGI-3: once the problem is interactive, intermediate behavior matters as much as the final answer.
6. The Messy Middle: What Still Breaks
This is the part most benchmark write-ups skip.
In early ARC-AGI-3-style systems, the hardest problems are not glamorous. They are operational:
- State drift: the agent forgets which hypotheses were already falsified and repeats them.
- Exploration debt: the agent spends too many actions discovering mechanics that could have been inferred from context.
- Credit assignment: when a task is solved or failed several steps later, it is hard to tell which earlier decision actually mattered.
- Overpowered planners: the planning module becomes so expensive that it destroys any benefit from a better policy.
- Deep-RL mismatch: reinforcement learning loops can improve policy quality, but they are costly to train, brittle to reward design, and often unnecessary for small structured environments.
That last point is worth stressing. Deep RL is tempting because ARC-AGI-3 looks like an environment benchmark, but not every environment problem needs an RL-heavy solution. In many cases, explicit memory plus constrained search gets you most of the value with far less tuning burden.
The benchmark becomes educational when you use it to compare these options honestly:
- a reactive one-step policy
- a stateful planner with explicit memory
- a graph-based multi-node controller
- an RL-trained policy with environment feedback
Without that comparison, it is too easy to mistake architectural complexity for progress.
7. What I Would Build Next
If you want to learn something real from ARC-AGI-3, start small.
Recreate one public environment. Log the full observation -> hypothesis -> action trace. Measure action count, failure recovery, and inference cost per episode. Then compare a plain stateful loop against a heavier graph-based controller.
That experiment will teach you more than a polished benchmark hot take, because it makes the trade-offs visible.
The useful version of ARC-AGI-3 is not "agentic engineering will transform everything." The useful version is much narrower: interactive benchmarks expose whether your system can build and update a working model of the world under tight action budgets.
That is a hard problem, and that is exactly why the benchmark is worth paying attention to.
If you want more articles in this format, I will keep publishing implementation-focused benchmark teardowns and workflow evaluation notes here on evallab.au.