
The State of AI Evaluations: March 2026 Report
In the first quarter of 2026, the AI evaluation landscape looks very different from even a year ago. Many older benchmarks are still useful as historical reference points, but they no longer do enough to separate the best models. The more informative tests now tend to measure one of four things: human preference, fresh problem-solving, real software work, or adaptation to unfamiliar tasks.
What matters now is not finding one benchmark to rule them all. It is understanding which benchmark exposes the failure mode you actually care about.
1. Human Preference: LMSYS Chatbot Arena
The LMSYS Arena is still one of the clearest signals for overall user preference because it relies on blind pairwise comparisons. It does not measure truth, depth, or coding ability directly. It measures which answer people prefer when they see two outputs side by side.
The ranking order changes often, so the exact top five matters less than the broader pattern: leading models are clustered tightly together, and small Elo gaps should not be over-interpreted.
What Arena is good for:
- catching differences in tone, helpfulness, and instruction-following
- reflecting what end users actually like
What Arena is not good for:
- measuring factual reliability
- proving deep domain expertise
- evaluating long-horizon task completion
If I were using Arena as part of a model selection stack, I would treat it as a first-pass preference signal and nothing more. It is useful when tone, helpfulness, and conversational feel matter. It becomes much less useful when the job is structured extraction, tool use, or long-horizon workflow execution. In those cases, the right next step is to assemble an internal eval set from real prompts and failure cases rather than extrapolating too much from Elo rank.
2. Real-World Coding: LiveCodeBench
Static coding benchmarks age badly because popular problems eventually leak into training data. LiveCodeBench addresses that by drawing on fresh competitive programming tasks, which makes it a better read on whether a model can solve unfamiliar coding problems.
This benchmark is useful, but only within its lane. It tells you a lot about algorithmic coding under pressure. It tells you less about whether a model can read a messy production codebase, work with an existing architecture, or resolve a real bug ticket without supervision.
If you build developer tools, LiveCodeBench is best treated as one signal, not the whole story.
That distinction matters in practice. A model can look excellent on fresh contest-style problems and still struggle with tasks like:
- tracing a regression across five files
- understanding a legacy abstraction nobody documented well
- making a small change without breaking adjacent behavior
Those are normal software engineering problems, and they are often a better proxy for real value than raw contest accuracy.
3. Agentic Engineering: SWE-bench Verified
SWE-bench Verified remains one of the most practical evaluations because it measures whether a model can help resolve real GitHub issues in real repositories. That is much closer to useful engineering work than answering isolated contest problems.
The leaderboard still matters here, but the more important insight is what the benchmark rewards: reading code, understanding context, making targeted edits, and staying coherent across a repository-level task.
For teams choosing models for coding agents, this is usually more relevant than raw benchmark scores on short algorithm questions.
It is also a reminder that the evaluation target has changed. The useful question is no longer just, "Can the model write code?" It is, "Can the model behave like a careful engineer inside an existing codebase?"
The detail I would check first is whether a reported SWE-bench result came from autonomous execution or from a human-assisted setup. That distinction matters more than most leaderboard summaries admit. A score achieved with hand-holding tells you something about ceiling performance; an autonomous score tells you much more about what a deployed coding agent will actually do inside a repository.
4. General Intelligence & Spatial Reasoning: ARC-AGI
ARC-AGI tests something different again: whether a system can infer and apply a new rule from a tiny number of examples. It is not a product benchmark, and it is not trying to simulate everyday chat use. Its value is that it pushes on adaptation rather than familiarity.
As with other difficult benchmarks, the exact ranking matters less than the direction of travel. The strongest systems now perform far better than early baselines, and much of that progress appears to come from better reasoning scaffolds and more test-time compute.
If you care about product decisions, ARC-AGI should be read as a research signal. It tells you something about adaptability and abstraction. It does not tell you whether a customer support bot will be better next week.
The Q1 2026 Snapshot
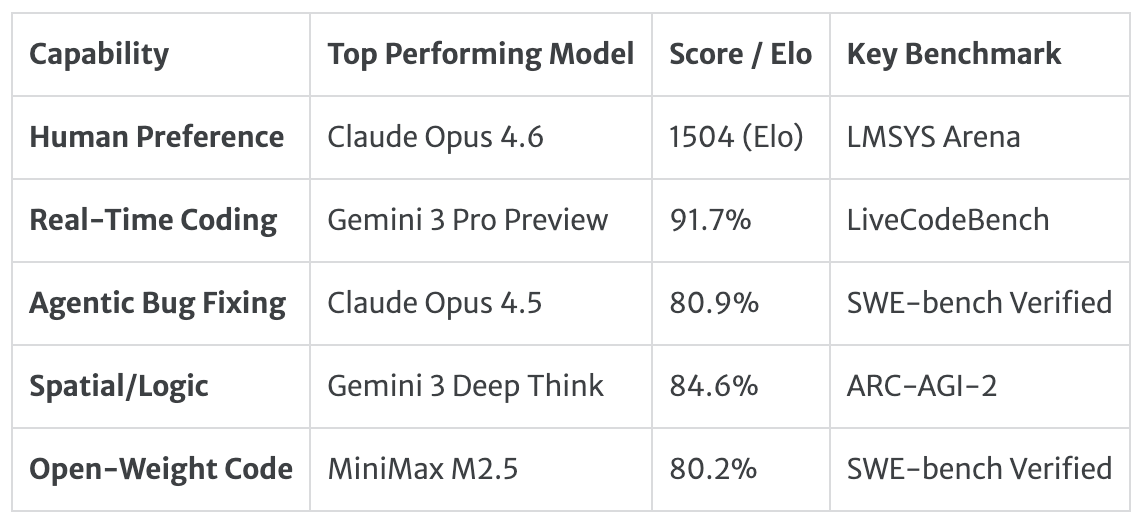
The 2026 Trend: Test-Time Compute
If there is one broad takeaway from 2026 so far, it is this: model quality is increasingly tied to how the system uses inference-time compute.
In plain terms, many of the biggest gains now come from giving models more room to reason, search, and verify before they answer. That shows up across coding, agentic engineering, and hard reasoning benchmarks.
For practitioners, the implication is simple:
- Do not judge a model only by its base version.
- Check whether the benchmark result depends on a higher-effort reasoning mode.
- Match the model configuration to the task. Fast mode and high-effort mode are often effectively different products.
Benchmarks are no longer just about the model. They are about the model plus the system wrapped around it.
How to Read Leaderboards Without Fooling Yourself
Most leaderboard mistakes come from over-reading a single number.
Here are three common failures:
- Treating small gaps as decisive. A tiny difference at the top of a leaderboard often says less than people think, especially when rankings shift frequently.
- Ignoring the evaluation setup. A result achieved with heavy reasoning mode, tool use, or long inference time may not reflect the experience you can actually ship.
- Assuming transfer where none is proven. A model that wins on Arena will not automatically win on coding agents. A model that wins on LiveCodeBench will not automatically be best for legal review.
The right question is not "Who is number one?" The right question is "Which benchmark best matches the kind of failure I care about?"
A Practical Evaluation Stack
If you are choosing models for real work, a simple evaluation stack is usually better than chasing one perfect benchmark.
For most teams, that stack looks like this:
- One public preference benchmark to understand general user-facing quality
- One task benchmark that matches your domain, such as coding, search, or workflow completion
- One internal eval set made from your own prompts, documents, and failure cases
- One cost-and-latency pass so you understand what the best score actually costs you in production
That last step is easy to skip and usually a mistake. A model that is best in theory but too slow or expensive in your real workflow is not actually your best option.
This is where 2026 feels different from earlier waves of AI benchmarking. The conversation is moving away from "Which base model is smartest?" and toward "Which full system performs best under the constraints I actually have?"
If I were turning this article into a reusable workflow, the logic would be simple: start with one public benchmark for broad orientation, add one task-specific benchmark for the capability you care about, run an internal eval set on real examples, then measure cost and latency under the exact inference mode you plan to ship.
That is usually enough to avoid most leaderboard mistakes.