The Wall Between Mimicry and Mind: What ARC-AGI-2 Tests and Why It Matters
What is ARC-AGI-2?
Imagine I show you three pairs of pictures. In each pair, a blue square moves to the right and turns red when it hits a yellow line. Then, I give you a fourth picture with a blue square and a yellow line and ask, "What happens next?"
Most people solve that kind of pattern quickly. Not because they memorized it, but because they can infer a rule from a few examples and apply it to a new case.
That is the basic intuition behind ARC-AGI-2. It is a benchmark built around small visual puzzles that try to measure whether a system can infer a new rule from very little data and then use it correctly.
The benchmark matters because it tries to isolate a capability that standard language-heavy tests often blur together: adaptation to something genuinely new.
At a high level, ARC-AGI-2 tasks:
- Require no language: No English, no math formulas, no trivia.
- Minimize "Crystallized" Knowledge: It doesn't care what you've memorized.
- Maximize "Fluid" Reasoning: It only cares how fast you can adapt to a brand-new logic you’ve never seen before.
How an ARC Task Feels in Practice
If you have never looked closely at ARC before, the benchmark can seem more mysterious than it really is.
Each task usually gives you a few input-output examples. You see a small colored grid on the left, then the correctly transformed grid on the right. Your job is to infer the rule connecting them and apply that rule to a new input.
For example, a task might show:
- one grid where the only red object gets mirrored horizontally
- another where a blue shape is copied into each corner
- a third where a separator line tells you which region of the grid should change
Then the test case arrives with a new arrangement, and the model has to decide what the rule really was.
This is what makes ARC interesting. The hard part is usually not drawing the final answer. The hard part is identifying the right abstraction:
- Is the rule about color?
- Is it about shape?
- Is it about counting objects?
- Is it about symmetry or containment?
- Or is one object actually acting as an instruction for what to do to another?
Humans are often surprisingly good at this kind of shift because we naturally look for the simplest explanation that fits all examples. Models tend to struggle more when there are several plausible patterns and only one of them generalizes correctly.
Why did we need a Version 2?
The original ARC became influential because it aimed at a hard problem: testing generalization rather than recall. But once a benchmark becomes famous, it also becomes easier to game. Researchers found that some systems could make progress through brute-force program search, heavy tuning, or familiarity with the public task set.
ARC-AGI-2 was meant to raise the bar. It pushes harder on the kinds of reasoning that are difficult to fake:
- Symbolic Interpretation: A color isn't just a color. A green pixel might be a "key," and a red pixel a "door." The AI must realize the meaning of the symbol, not just the pattern of the pixels.
- Compositional Reasoning: Instead of one simple rule, tasks now require applying multiple rules that interact. If rule A happens, rule B changes. It's like playing a game where the physics change mid-level.
- Contextual Rule Application: Rules are no longer global. A rule might apply to the top half of the grid but not the bottom, requiring the AI to understand "where" and "why" it’s solving a specific part of the puzzle.
In plain English: the puzzles are designed so that a model has to figure out what matters, what the rule is, and where that rule applies.
What the Recent Progress Means
Recent results show that frontier systems are much better at ARC-style tasks than they were a year ago. That progress is real, but it needs to be interpreted carefully.
The main shift is not just bigger training runs. It is what happens at inference time. Strong systems increasingly use some form of extra search, extra reasoning, or task-specific adaptation before producing an answer.
That matters because ARC-AGI-2 is unusually sensitive to how a model uses its test-time compute. A system that pauses, searches, and checks intermediate hypotheses can perform very differently from one that simply gives its first guess.
Current Snapshot
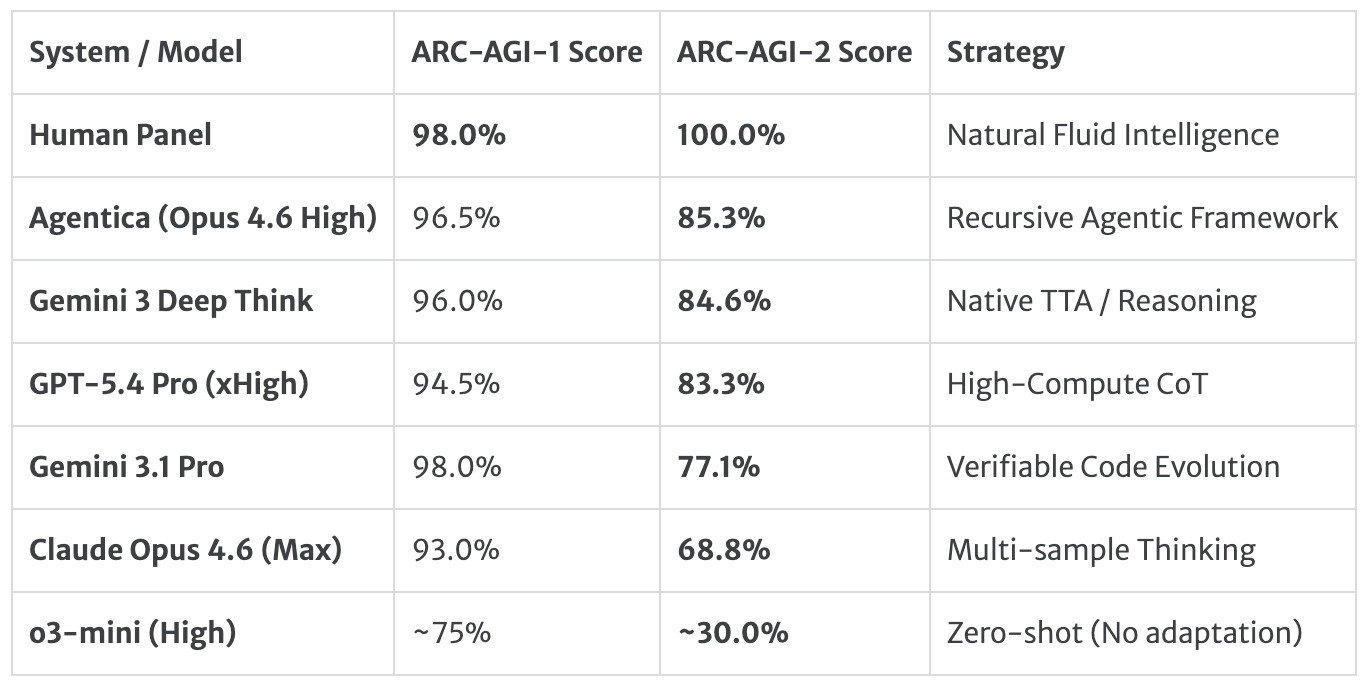
The practical takeaway: strong ARC-AGI-2 performance increasingly reflects the full system around the model, not just the base model by itself.
If I were evaluating a claimed ARC-AGI-2 improvement, the first thing I would check is the inference configuration that produced it. A result achieved with extended reasoning or heavy test-time search is a signal about adaptive reasoning capability, but it is not automatically a promise about latency, cost, or production behavior at default settings.
That is useful for evaluation, but it also means leaderboard numbers need context. A higher score may reflect better reasoning scaffolding, more search, more adaptation, or simply more computation at test time.
This is especially important if you are comparing products. A model that performs well on ARC-AGI-2 with substantial test-time search is not the same thing as a low-latency assistant that can give you a reliable answer instantly in production.
Why This Matters
François Chollet often describes the difference this way:
- Current AI is like a massive road network. It can get you from Point A to Point B very fast, provided the road has already been built (trained).
- AGI is like a road-building company. It can go into a trackless forest where no roads exist and build a path on the fly.
ARC-AGI-2 is trying to measure more of the second skill than the first.
That does not mean success on ARC-AGI-2 automatically equals AGI. It is still a narrow benchmark with small visual tasks. But it is useful precisely because it asks a harder question than most mainstream tests: can the system adapt when there is no familiar template to lean on?
For developers and evaluators, that makes ARC-AGI-2 worth watching. If a model improves here, it is at least some evidence that it is getting better at flexible problem-solving rather than just getting better at imitating known answers.
What ARC-AGI-2 Does Not Tell You
It is also worth being clear about the limits.
ARC-AGI-2 does not tell you whether a model is good at:
- writing production code
- following vague business instructions
- being safe or reliable in customer-facing applications
- maintaining long conversations
- working well inside real tools and workflows
That is why it should not be treated as a universal benchmark. It is best seen as a sharp probe for one specific capability: flexible abstraction from minimal examples.
This distinction matters because benchmark conversations often get sloppy. People jump from "the model improved on ARC" to "the model is broadly more intelligent." That might be partly true, but the benchmark alone cannot justify the whole claim.
How to Use It Practically
If you build with models, ARC-AGI-2 is most useful as a diagnostic benchmark, not a product KPI.
Use it when you want to understand whether a system is improving at:
- adapting to unfamiliar tasks
- testing multiple hypotheses before answering
- extracting the right rule from very little data
Do not use it as your only decision tool when choosing a model for support, search, coding, or document workflows. In those settings, you still need product-specific evaluations.
The practical read is simple:
- If a model improves on ARC-AGI-2, pay attention.
- If that improvement only appears with very high inference cost, keep that in mind.
- If you care about real deployment, pair ARC-style results with task-specific tests from your own workflow.
If I were expanding this article further, I would add a small solver trace showing three candidate abstractions for one ARC task and why only one of them generalizes. That would make the benchmark's core difficulty more concrete than a score table alone.